Efficacité de stockage avec Qumulo
Lorsque Qumulo vous indique la capacité utilisable de votre système de stockage, nous voulons dire exactement cela: c'est la capacité que vous pouvez utiliser pour stocker des fichiers. Cela semble simple, mais c'est une déclaration que de nombreux concurrents ne peuvent pas faire. En fait, compte tenu des inefficacités des méthodes traditionnelles de protection des données et des problèmes de performances qui peuvent découler d'une utilisation complète, la plupart des fournisseurs de stockage vous obligent à laisser jusqu'à 30% de votre capacité inutilisée. Dans un monde où vous avez besoin de toutes vos données à portée de main, c'est un déficit majeur.
Nous aimerions expliquer comment Qumulo permet de s'appuyer sur toute votre capacité utilisable pour les fichiers, même à l'échelle du pétaoctet, sans sacrifier les performances ou la protection des données. Cela est vrai, quel que soit le nombre de fichiers que vous stockez, ou leur taille. En fait, vous pouvez stocker des milliards de petits fichiers tout aussi efficacement que les gros. C'est votre stockage. Vous pouvez l'utiliser comme votre entreprise l'exige, et vous pouvez l'utiliser tout. Après tout, la gestion du stockage peut être assez complexe sans se demander si la «capacité utilisable» signifie vraiment ce qu’elle est censée faire.
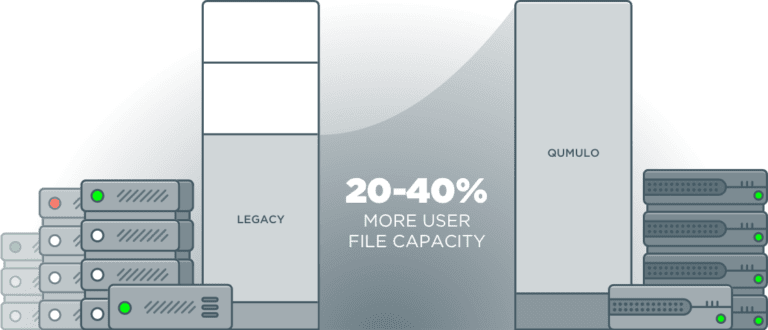
Pourquoi les solutions de stockage évolutives héritées sont conçues pour les capacités perdues
La différence entre Qumulo et les fournisseurs de stockage traditionnels est profondément enracinée, en raison de différences fondamentales dans leurs approches en matière de protection des données, de stockage de petits fichiers et d'opérations de reconstruction. Nous allons en discuter un par un.
Protection traditionnelle des données: de grossièrement inefficace à légèrement moins inefficace
La protection des données est clairement non négociable. Tous les systèmes de stockage de fichiers de niveau entreprise sont conçus pour empêcher la perte de données en cas de panne des disques, et tous reposent sur une forme quelconque de redondance ou de duplication des informations entre les périphériques de stockage. L'approche utilisée, cependant, fait une énorme différence dans l'efficacité de la protection des données, définie comme la quantité de données stockées divisée par la capacité totale du disque utilisée.
Reflétant, la forme la plus rudimentaire de protection des données, repose sur la création de plusieurs copies complètes des données protégées. Chaque copie réside sur un disque différent afin de pouvoir être récupéré si l'un des disques échoue. Ceci est efficace en termes de récupération, mais il est extrêmement inefficace, réduisant de moitié la capacité disponible pour le stockage de fichiers.
La double mise en miroir, qui conserve trois copies des données pour les protéger contre deux pannes de disque simultanées, est beaucoup plus efficace pour la restauration, mais aussi beaucoup plus inefficace, laissant les deux tiers de la capacité «utilisable» indisponibles pour les fichiers. Dans ce cas, la mise en miroir pour la protection à deux lecteurs nécessite 3TB de capacité brute pour stocker les To de données de fichier.
À l'échelle du pétaoctet, il est évidemment préférable d'éviter autant que possible la mise en miroir, afin d'éviter de gaspiller les deux tiers de votre budget en stockage que vous ne pouvez pas utiliser pour stocker des fichiers.
Codage d'effacement (CE) est l'alternative la plus connue pour la protection des données, plus efficace que la mise en miroir, plus rapide et plus configurable. Un avantage clé d'EC est la flexibilité qu'il offre. Les administrateurs peuvent décider du bon équilibre entre performances, temps de récupération en cas de défaillance des supports physiques et nombre de défaillances simultanées autorisées.
En travaillant au niveau du bloc plutôt qu'au niveau du fichier, EC permet de protéger efficacement les données sans avoir à créer une copie personnalisée du volume de données complet. Au lieu de cela, les données de bloc sont codées dans des segments partiellement redondants stockés sur des supports physiques distincts. Dans l'exemple le plus simple, connu sous le nom de codage (3, 2), trois blocs de stockage sont utilisés pour coder en toute sécurité deux blocs de données utilisateur; le troisième bloc, appelé «bloc de parité», est utilisé pour la récupération.
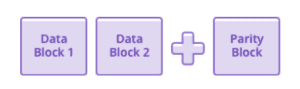
Le contenu du bloc de parité est calculé par l'algorithme de codage d'effacement. Même ce schéma simple est plus efficace que la mise en miroir: vous n'écrivez qu'un seul bloc de parité pour deux blocs de données. Dans un codage (3, 2), si le disque contenant l'un des trois blocs échoue, les données utilisateur des blocs 1 et 2 sont sûres.
Voici comment cela fonctionne. Si le bloc de données 1 est disponible, alors vous le lisez simplement. La même chose est vraie pour le bloc de données 2. Cependant, si le bloc de données 1 a été perdu, le système EC lit le bloc de données 2 et le bloc de parité, puis reconstruit la valeur du bloc de données 1. De même, si le bloc de données 2 réside sur le disque défaillant, les systèmes lisent le bloc de données 1 et le bloc de parité.
Un encodage (3, 2) a un rendement de 67 pour cent - en d'autres termes, les deux tiers de votre stockage disponible peuvent être utilisés pour les données utilisateur, tandis que le tiers restant est utilisé pour la protection des données. L'ajout de disques peut améliorer le niveau de protection. Par exemple, un encodage (6, 4), qui a le même rendement 67 que (3, 2), peut tolérer deux pannes de disque au lieu d'un seul. En d'autres termes, même si deux disques tombent en panne en même temps, le système peut toujours fonctionner sans temps d'arrêt ou perte de données. La protection supplémentaire sans réduction d'efficacité n'est pas un repas gratuit: le processus de récupération des données encodées (6, 4) nécessite plus de travail que dans le cas de l'encodage (3, 2), ce qui signifie que le temps de reconstruction est plus long .
En matière de stockage de qualité professionnelle, EC peut fournir des rendements très élevés. Par exemple, l'encodage (16, 14) a un rendement d'environ 85 pour cent, et permet toujours jusqu'à deux pannes de disque simultanées sans perte de données.
À ce stade, l'efficacité de stockage en pourcentage de 85 peut sembler très bonne, en particulier par rapport à l'efficacité en pourcentage de 33 de la protection à deux disques utilisant la mise en miroir. Si vous avez besoin de stocker à propos de 1PB de fichiers, 1.2PB de capacité brute devrait le couvrir, non? Pas nécessairement. Encore une fois, la réalité derrière les chiffres est moins claire que cela pourrait paraître.
Stockage de fichiers de petite taille: une autre manière dont les fournisseurs hérités sous-traitent la capacité utilisable
Bien que votre fournisseur de stockage puisse signaler une capacité utilisable comme tout ce qui reste après avoir autorisé les bits de parité de codage d'effacement, ne supposez pas que vous pouvez réellement utiliser tout cet espace. Il s'avère que les systèmes de stockage évolutifs hérités ne font pas un très bon travail en ce qui concerne les petits fichiers. Par petit, on entend tout ce qui est sous 128KB.
Il y a une raison simple à cela. Les systèmes de stockage existants reposent sur une conception vieille de plusieurs décennies qui les oblige à mettre en miroir (ou à double miroir, voire à triple miroir) des fichiers plus petits que 128KB. Nous avons déjà discuté des inefficacités de la mise en miroir - il s'avère maintenant que cela peut poser problème même avec la protection des données EC. Voici le pire: l'espace nécessaire pour cette mise en miroir est déduit de la capacité utilisable signalée par le fournisseur. C'est comme acheter un sandwich, puis découvrir quand vous le déballez qu'il manque un gros morceau.
Quelle est la taille de cette morsure manquante? C'est un autre problème: vous n'avez aucun moyen de savoir. Vous devez déterminer à l'avance la taille exacte de chaque fichier que vous prévoyez d'écrire pour connaître le nombre de fichiers inférieurs à ce seuil 128KB, et il n'y a aucun moyen de le prévoir. Par conséquent, il est impossible de savoir quelle capacité utilisable vous avez réellement ou quand vous en manquerez. Au lieu de cela, vous aurez besoin de surprovision pour vous assurer que vous êtes couvert. Cela signifie que vous gaspillez de l’argent de deux manières: l’une, pour la capacité «utilisable» que vous perdez à cause de la moindre erreur de stockage de fichiers, et deux pour la capacité supplémentaire que vous achetez en tant que coussin.
Ce n'est pas un moyen de gérer une entreprise à forte intensité de données.
Recréer les opérations: le coût caché de la récupération de disque
Les fournisseurs de stockage existants peuvent disposer d’un moyen supplémentaire pour récupérer la capacité utilisable promise. De nombreux systèmes consomment de la capacité de stockage pour les opérations de reconstruction lors de la récupération après une panne de disque. Si la capacité disponible est insuffisante, le système aura du mal à terminer la récupération. Pour cette raison, la plupart des fournisseurs recommandent de limiter votre utilisation à 80 pour cent de la capacité utilisable promise. Encore une fois, cela remet en question la définition du mot «utilisable» par le fournisseur.
Comment Qumulo est-il différent? La capacité utilisable signifie la capacité utilisable
Qumulo est un autre type de société de stockage de fichiers. Nous pensons que la capacité utilisable signifie exactement cela: la quantité d'espace sur laquelle vous pouvez compter pour stocker des fichiers. Avec Qumulo système de fichiers moderne et évolutif, vous pouvez utiliser 100 pour cent de la capacité utilisable pour les fichiers. Voici pourquoi.
Protection plus intelligente des données au niveau des blocs
Alors que les fournisseurs de stockage hérités se concentrent sur l'amélioration progressive de l'efficacité, Qumulo a perturbé le secteur avec une approche fondamentalement différente. Au lieu de protéger les données au niveau des fichiers comme le font d’autres, Qumulo protège à la fois niveau bloc, permettant des gains typiques du pourcentage d'utilisation de 20 pour les fichiers volumineux. Et ce chiffre double lorsque de petits fichiers entrent en scène.
Stockage de petits fichiers à haute efficacité
Lors de la gestion de petits fichiers, la protection au niveau des blocs offre une efficacité de stockage allant jusqu’à 40, au-delà de la protection basée sur les fichiers. Cela est particulièrement utile à l'ère des données générées par les machines, qui se présentent généralement sous la forme d'un grand nombre de petits fichiers.
Voici un exemple d'un client d'entreprise réel (avant son arrivée à Qumulo).
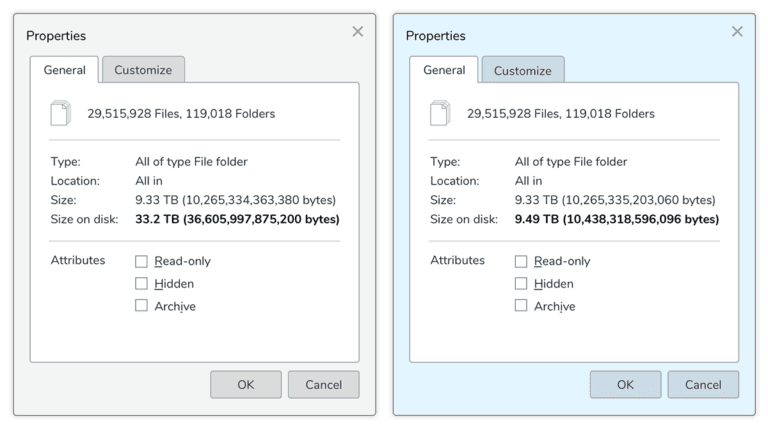
Ce client a migré environ un million de petits fichiers 30 d'un cluster de stockage hérité vers un cluster Qumulo. La boîte de dialogue de gauche indique la quantité d'espace occupée par ces fichiers sur le système du fournisseur hérité, qui reflète les petits fichiers. La zone à droite indique la quantité d'espace occupée par les fichiers sur le cluster Qumulo. Comme vous pouvez le constater, le système du fournisseur hérité avait besoin de plus de trois fois plus d'espace pour stocker les mêmes fichiers, soit une capacité 33.2TB complète utilisable pour 9.33TB des données de fichier. Sur le cluster Qumulo, il n'a fallu que 9.49TB.
C'est mieux comme ça.
En fait, avec Qumulo, il n’ya aucune différence d’efficacité de stockage entre les gros et les petits fichiers.
Il est donc beaucoup plus simple d’estimer la quantité de mémoire dont vous aurez besoin. Au lieu de vous confronter à des estimations complexes de la combinaison de fichiers volumineux et de fichiers volumineux dans votre charge de travail et d’espérer qu’ils ne soient pas trop loin du but, vous pouvez simplement consulter l’interface utilisateur Web pour voir combien d’espace est disponible. Vos fichiers stockés occuperont la même quantité d’espace, qu’ils soient grands ou petits.
Reconstruire des opérations qui ne réduisent pas la capacité utilisable
Avec Qumulo, il n’est pas nécessaire de mettre de côté une capacité utilisable pour des tâches administratives telles que la reconstruction. Au lieu de cela, le système met de côté l'espace dont il a besoin avant de signaler la capacité utilisable. Cela signifie que vous pouvez effectuer une récupération après une panne de disque, même si le système est saturé à 100, sans avoir à surveiller l'espace disponible. Qumulo fournit également des reconstructions plus rapides que le RAID traditionnel, et n'introduit pas de points chauds de performances après une panne de disque.
Performances maximales pour un pourcentage d'utilisation 100
Le compromis entre utilisation et performances est bien connu des administrateurs de stockage. De nombreux systèmes de scale-up, RAIDLes systèmes à base de données et certains des systèmes de fichiers open source les plus populaires subissent une dégradation des performances au fur et à mesure que le système de fichiers se remplit. Pour éviter les problèmes de performances, vous devez rester sous 70 pour cent de la capacité utilisable. Vous ne devriez pas avoir à choisir entre l'utilisation et les performances, mais c'est la position que beaucoup de fournisseurs vous placent.
Contrairement à certains autres systèmes, les performances de Qumulo ne se dégradent pas lorsque votre système se remplit. Au lieu de conserver 30% de votre capacité en réserve, vous pouvez continuer et en utiliser 100%, en stockant des milliards de fichiers sans impact sur les performances.
Que signifie Qumulo pour vos données?
Tout compte fait, les avantages d'efficacité combinés signifient qu'un client Qumulo typique peut stocker la même quantité de données utilisateur avec 25 pour cent moins de capacité brute que les autres systèmes de fichiers.
Cette efficacité élevée est complétée par les avantages importants pour les entreprises à forte intensité de données:
- Temps de reconstruction rapide en cas d'échec du lecteur de disque
- La possibilité de continuer les opérations de fichiers normales pendant les opérations de reconstruction
- Aucune dégradation des performances due aux conflits entre les écritures de fichier normales et les reconstructions-écritures
- Efficacité de stockage égale pour les petits et les grands fichiers
- Rapport précis de l'espace utilisable
- Transactions efficaces permettant aux grappes Qumulo de s’adapter à plusieurs centaines de nœuds
- Une hiérarchisation intégrée des données chaudes / froides qui fournit des performances Flash aux prix des archives.
Vos données sont trop importantes pour être laissées à des méthodes de stockage obsolètes ou à des fournisseurs ne maîtrisant pas le concept de «capacité utilisable». Qumulo vous apporte la transparence, la prévisibilité et les performances dont vous avez besoin pour les opérations de données de l'ère numérique.