Présentation technique
Qumulo Core est une plate-forme de données de fichiers hautes performances. Voici comment cela fonctionne.
Notre mission: Permettre aux créateurs et aux innovateurs
Notre objectif chez Qumulo est de rendre le complexe radicalement simple. Nous voulons simplifier la sécurisation de vos données. Nous voulons simplifier l'adoption de nouvelles plateformes. Nous voulons simplifier le service des flux de travail exigeants (à faible coût). Nous voulons simplifier le cloud hybride.
La mission de Qumulo est d'aider les innovateurs à libérer la puissance de leurs données où qu'elles se trouvent. Les innovateurs créent de nouvelles entreprises, des traitements, des produits et de l'art en transformant les données en valeur. Cette transformation s'articule autour d'un cycle de vie des données où les collaborateurs capturent, interagissent, transforment, publient, puis archivent leurs données. Dans ce cycle de vie, les «créateurs» (artistes, chercheurs, etc.) utilisent les données numériques pour faire leur travail. Nous voyons cette transformation en action dans plusieurs industries.
Life Sciences
Les scientifiques explorent les données capturées à partir de séquenceurs pour identifier les anomalies, puis calculent des clusters transforment les données brutes en découvertes finies. Ces découvertes sont publiées dans la communauté des chercheurs, puis les données sont archivées.
Media and Entertainment
Les artistes modifient les données capturées lors des tournages quotidiens pour créer des scènes initiales, puis les pipelines de rendu les transforment en film fini. Les distributeurs publient ce film sur des points de vente en ligne et le contenu fini est archivé.
Fabrication et IoT
Les journaux et les images sont générés à partir de capteurs (avec un volume, une vitesse et une variété élevés) et analysés en temps réel pour détecter les pannes de composants. Plus tard, les analystes commerciaux examinent les données pour explorer les opportunités d'amélioration des processus et par les scientifiques des données pour créer de meilleurs modèles d'apprentissage automatique. Ces modèles sont publiés dans la ligne de fabrication pour améliorer l'efficacité de la production, et les journaux et images finis sont archivés.
Exigences d'une plate-forme de données de fichiers
Pour innover, les organisations dépendent de plates-formes de données de fichiers non structurées. Ces plates-formes fournissent un stockage persistant pour les données qui alimentent l'innovation. Ils offrent un accès facile, rapide et fiable aux créateurs et aux fermes de calcul qui transforment les données en découverte. Les innovateurs exigent que leurs plateformes de données non structurées :
Soyez prêt pour le cloud
Les plates-formes doivent être conçues pour les infrastructures de cloud public, privé et hybride, offrant des services de données non structurés dans le cloud public et dans le centre de données. Ils doivent également s'intégrer parfaitement à l'écosystème des services cloud (par exemple, les services d'apprentissage automatique (ML), de publication ou de stockage d'objets cloud).
Escaliers intérieurs
Les plates-formes doivent pouvoir servir des pétaoctets de données, des milliards de fichiers, des millions d'opérations et des milliers d'utilisateurs.
Travailler avec des outils standards
Les créateurs les plus précieux d'une organisation innovante (artistes, chercheurs, data scientists et analystes) doivent pouvoir utiliser leurs outils sans avoir à installer des pilotes personnalisés ou à modifier leur flux de travail.
- Fournir visibilité et automatisation
Les administrateurs doivent pouvoir créer, gérer et supprimer des services de données à l'aide d'API RESTful. Ils doivent être capables de comprendre les performances et l'utilisation de la capacité de leurs services de données en temps réel afin de mieux diagnostiquer les problèmes et planifier l'avenir.
- Sécurisé et prêt pour l'entreprise
Les données sont la pierre angulaire des organisations innovantes et doivent donc être protégées à l'aide d'outils d'identité et de cryptage standard. La plate-forme de données doit répondre aux exigences de l'entreprise en matière de reprise après sinistre, de sauvegarde et de gestion des utilisateurs.
Les défis des solutions existantes
Les organisations qui prospèrent sur les données pour stimuler l'innovation sont mal servies par les plates-formes de données non structurées disponibles.
Les plates-formes de données de fichiers open source et basées sur Windows évoluent mal, sont difficiles à provisionner automatiquement et nécessitent une gestion importante.
Les plates-formes de données de fichiers héritées basées sur des appliances matérielles manquent de fonctionnalités de visibilité en temps réel, offrent des surfaces d'API incomplètes et ne peuvent prendre en charge les charges de travail du cloud public que via des offres de matériel en tant que service adjacentes au cloud. Les variantes de mise à l'échelle telles que NetApp ont du mal à faire évoluer les espaces de noms uniques au-delà de 100 To.
Les services d'objets et de fichiers cloud prennent en charge de nombreuses charges de travail d'innovation cloud, mais ne permettent pas aux créateurs d'utiliser leurs outils standard, principalement en raison du manque de prise en charge des fichiers multiprotocoles. En outre, ils manquent de nombreuses fonctionnalités de sécurité et d'entreprise dont les entreprises ont besoin pour déplacer les charges de travail vers le cloud public.
Les magasins d'objets sur site offrent un stockage de données à faible coût, mais sont fondamentalement inadaptés aux étapes interactives et transformatrices du cycle de vie des données en raison de performances médiocres et d'un manque de prise en charge des outils standard pour les utilisateurs finaux.
Architecture logicielle de Qumulo
Qumulo a été fondé pour donner aux créateurs une plate-forme de données non structurée pour les clouds privés et publics.
Nous conditionnons cette plate-forme dans des produits évolutifs prêts pour le cloud qui permettent aux créateurs d'utiliser des outils essentiels. Nous fournissons également des API robustes pour la gestion et la visibilité en temps réel de l'utilisation du système, et répondons aux exigences de sécurité et de protection des données des entreprises du Fortune 500.
Le but de cet article est de fournir un aperçu de l'architecture de la plate-forme de données de fichiers de Qumulo afin d'illustrer comment notre produit offre les avantages susmentionnés aux innovateurs et aux créateurs. Pour illustrer la différenciation architecturale et la valeur de notre plateforme, nous explorerons les principales couches de notre logiciel. À chaque couche, nous décrirons l'objectif de la couche, la manière dont elle fournit des éléments de notre proposition de valeur et l'innovation qui anime cette valeur.
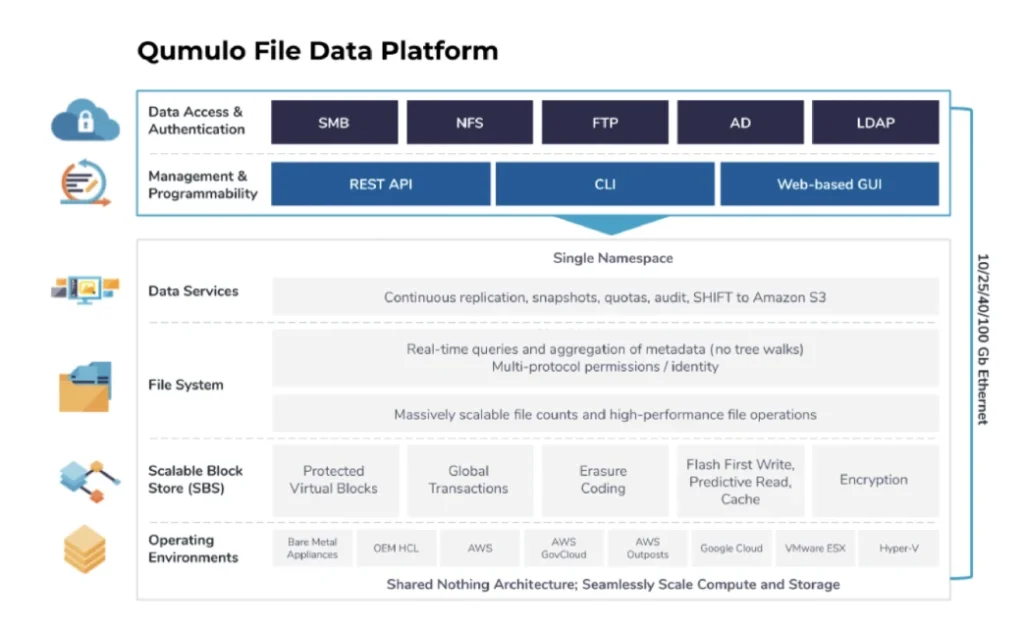
Principes de base de la plate-forme de données de fichiers Qumulo
Avant de plonger dans les composants individuels de la plate-forme de données de fichiers, il existe plusieurs hypothèses fondamentales qui sont importantes pour comprendre l'architecture Qumulo:
1. Qumulo fournit un système distribué qui présente un espace de noms unique. La plate-forme de données de fichiers de Qumulo se compose de clusters sans partage de nœuds indépendants. Chaque nœud offre capacité et performances. Les nœuds individuels restent en coordination constante les uns avec les autres. N'importe quel client peut se connecter à n'importe quel nœud et lire et écrire dans l'espace de noms.
2. La plate-forme de données de fichiers de Qumulo est optimisée pour l'échelle. Nous nous assurons que tous les aspects de notre produit peuvent confortablement prendre en charge des pétaoctets de données, des milliards de fichiers, des millions d'opérations et des milliers d'utilisateurs.
3. La plate-forme de données de fichiers de Qumulo est hautement disponible et immédiatement cohérente. La plate-forme de données non structurées de Qumulo est conçue pour résister aux défaillances des composants de l'infrastructure tout en fournissant un service fiable aux clients. Pour ce faire, nous utilisons l'abstraction logicielle, le codage d'effacement, les technologies réseau avancées et des tests rigoureux. Lorsque des données sont écrites dans le logiciel de Qumulo, nous ne reconnaissons pas cette écriture dans le service, l'utilisateur ou le nœud de calcul tant que nous n'avons pas stocké ces données dans un stockage persistant. Ainsi, toute lecture sera d'une vue cohérente des données (par opposition aux modèles éventuellement cohérents).
4. Qumulo fournit des logiciels conçus pour le cloud public, privé et hybride. Le logiciel de Qumulo fait peu d'hypothèses sur la plate-forme sur laquelle il s'exécute. Il fait abstraction des ressources matérielles physiques ou virtuelles sous-jacentes afin de tirer parti de la meilleure infrastructure de cloud public et privé. Cela nous permet de tirer parti de l'innovation rapide dans les technologies de calcul, de mise en réseau et de stockage pilotée par les fournisseurs de cloud et l'écosystème des fabricants de composants.
5. La plate-forme de données de fichiers Qumulo est API-first. Chaque fonctionnalité créée par Qumulo apparaît d'abord sous forme de points de terminaison d'API. Nous présentons ensuite un ensemble organisé de ces points de terminaison dans notre interface de ligne de commande (CLI) et notre interface visuelle. Cela inclut la création du système, la gestion des données, l'analyse des performances et de la capacité, l'authentification et l'accessibilité des données.
6. Qumulo expédie de nouveaux logiciels rapidement et régulièrement. Nous publions de nouvelles versions de notre logiciel toutes les deux semaines. Cela nous permet de répondre rapidement aux commentaires des clients, d'améliorer constamment notre produit et d'exiger de nos équipes un code de qualité de production.
7. L'équipe de réussite client de Qumulo est très réactive, connectée et agile. Chaque plate-forme de données de fichiers de Qumulo a la capacité de se connecter à la surveillance à distance via notre service de surveillance basé sur le cloud Mission Qontrol. Notre équipe de réussite client utilise ces données pour aider les clients à résoudre les incidents, fournir des informations sur l'utilisation des produits et alerter les clients lorsque leurs systèmes rencontrent des défaillances de composants. Cette combinaison d'assistance intelligente et d'innovation produit rapide permet d'obtenir un score NPS de 80+, le meilleur du secteur.
Accès aux données et authentification
Objectif
Permettez l'accès aux données à l'aide d'applications et de systèmes d'exploitation standard tout en garantissant un contrôle d'identité de niveau entreprise.
Comment ça marche
Notre couche d'accès aux données prend en charge les trois protocoles d'accès aux fichiers les plus couramment adoptés par les créateurs (NFS, SMB et FTP). Ces protocoles existent en tant que ressources indépendantes et évolutives sur chaque nœud d'un cluster Qumulo. Les utilisateurs finaux voient un espace de noms unique qui peut augmenter en capacité et en performances. Cet espace de noms est accessible de manière transparente à partir de n'importe quel appareil informatique Windows, Mac ou Linux et, par conséquent, de toute application de données non structurée.
Notre couche d'authentification prend en charge les deux services d'identité standard de l'industrie: Active Directory (AD) et Lightweight Directory Access Protocol (LDAP). Les services de données de Qumulo s'intègrent à ces systèmes d'identité mondiaux tels qu'ils sont gérés par les clients, ce qui permet de contrôler l'accès entre le calcul, les utilisateurs finaux et les données. La connexion de la plate-forme de données de fichiers Qumulo aux services d'identité nécessite une configuration simple et fonctionne bien avec des configurations de services d'identité complexes et distribués (un défi courant dans les environnements de cloud privé et public d'entreprise).
Chaque protocole d'accès aux données utilise une couche d'authentification commune pour interagir avec les données stockées dans notre plateforme de données de fichiers. Cela permet aux utilisateurs de se déplacer entre les applications, les systèmes d'exploitation et les environnements, tout en accédant aux mêmes données. Au fur et à mesure que les données se déplacent tout au long du cycle de vie des données (de la capture à la transformation et à l'archivage), cette séparation des couches offre une flexibilité critique et réduit le nombre de systèmes que les clients doivent maintenir.
Points d'innovation
Les protocoles d'accès aux données de Qumulo permettent aux utilisateurs d'exploiter n'importe quel système d'exploitation Windows, Mac ou Linux standard et n'importe quelle application standard sans apporter de modifications à leur environnement.
Qumulo prend en charge les protocoles d'accès aux données avec état (SMB) et sans état (NFS) à partir du même espace de noms évolutif.
Qumulo permet une gestion des identités de niveau entreprise dans un système évolutif avec une haute disponibilité.
Gestion et programmabilité
Objectif
Permettez aux propriétaires d'applications de créer des solutions intégrées avec la plate-forme de données de fichiers Qumulo et permettez aux administrateurs d'automatiser et de gérer leurs services de données.
Comment ça marche
La couche de gestion et de programmabilité est composée de trois capacités; une API REST, une interface de ligne de commande (CLI) et une interface visuelle.
L'API REST
L'API REST est un sur-ensemble de toutes les fonctionnalités de la plate-forme de données Qumulo. Depuis l'API, les clients peuvent:
- Créer un espace de noms (dans le cloud à l'aide d'un modèle Terraform ou Cloud Formation)
- Configurer tous les aspects d'un système (de la sécurité comme les services d'identité ou les rôles de gestion, à la gestion des données comme les quotas, à la protection des données comme les politiques de snapshot ou la réplication de données, à l'ajout de nouvelles capacités)
- Recueillir des informations sur leur système (y compris l'utilisation de la capacité et les hotspots de performances)
- Accéder aux données (y compris les opérations de lecture et d'écriture)
L'API est «auto-documentée», ce qui permet aux développeurs et aux administrateurs d'explorer facilement chaque point final (et voir des exemples de sorties). Qumulo maintient une collection d'exemples d'utilisation de notre API sur Github (https://qumulo.github.io/).
L'interface de ligne de commande (CLI)
La CLI Qumulo offre la plupart (mais pas la totalité) de l'API et se concentre sur les administrateurs système. La CLI offre une méthode d'interaction scriptable pour travailler avec un système Qumulo. La CLI propose environ 200 commandes uniques (à partir de Qumulo Core Version 3.0.3). Une liste complète des commandes peut être trouvée dans notre base de connaissances (www.care.qumulo.com).
L'interface visuelle
L'interface visuelle de Qumulo offre une manière centrée sur l'utilisateur d'interagir avec une plate-forme de données de fichiers Qumulo. L'interface visuelle est une interface Web, servie à partir du système, sans machine virtuelle ni service séparé. L'interface visuelle est organisée autour de six sections de navigation de haut niveau: Tableau de bord, Analytics, Partage, Cluster, API et outils et Support.
Tableau de bord
Ceci est la «page d'accueil» de l'interface visuelle de Qumulo. Il offre une série d'informations facilement compréhensibles sur l'activité, la croissance, les performances et la santé d'une plate-forme de données de fichiers Qumulo. Le tableau de bord visualise la capacité disponible et utilisée (y compris les données, les métadonnées et les instantanés), la croissance de la capacité et la croissance du nombre de fichiers, les performances globales du système et l'équilibre des charges de travail.
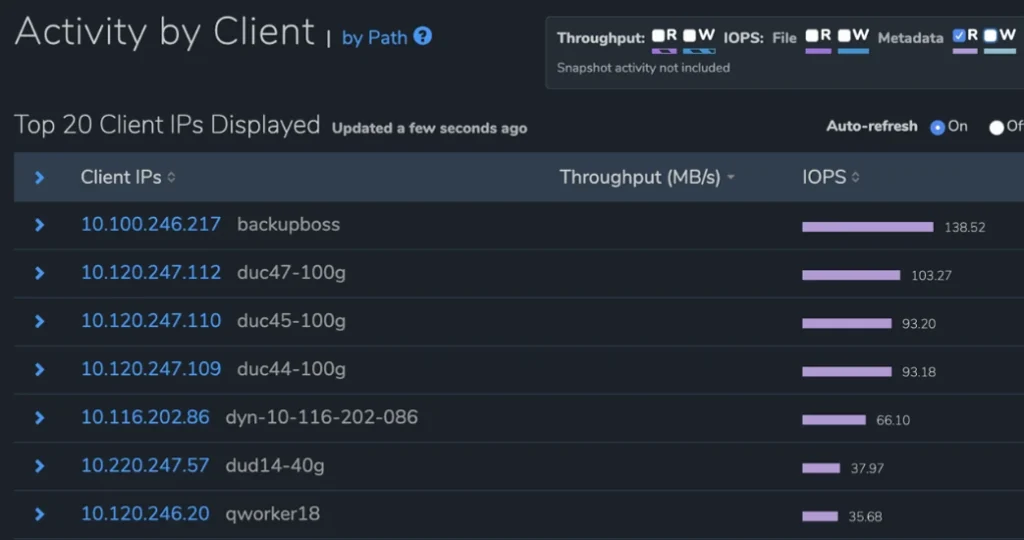
Analytique
Cette section offre aux administrateurs système une vue granulaire et en temps réel de leurs systèmes non disponibles sur d'autres plates-formes de données de fichiers. Ces analyses offrent une visibilité et un aperçu de l'utilisation des performances de chaque charge de travail (par client ou par chemin de données) et de la croissance de la capacité de leur système, y compris une vue des parties de la plate-forme de données de fichiers qui augmentent ou diminuent par période, permettant aux clients de déterminer quelles charges de travail consomment leur capacité.
Partager
Cette section permet aux administrateurs de rendre les données accessibles aux utilisateurs en créant des partages SMB et des exportations NFS. Il permet également aux administrateurs de gérer l'utilisation de la capacité via des quotas. Enfin, la section de partage permet aux administrateurs de gérer la connexion du cluster aux services d'identité AD et LDAP.
Grappe
Cette section permet aux administrateurs de configurer les politiques de cliché, les politiques de réplication continue, la mise en réseau et les services d'heure et de date. Cela leur permet de voir les nœuds du système et d'ajouter de nouveaux nœuds.
API et outils
Cette section permet aux clients de télécharger l'outil de ligne de commande Qumulo et d'explorer notre API d'auto-documentation. Il inclut la possibilité «d'essayer» chaque point de terminaison et de voir des exemples de sorties JSON.
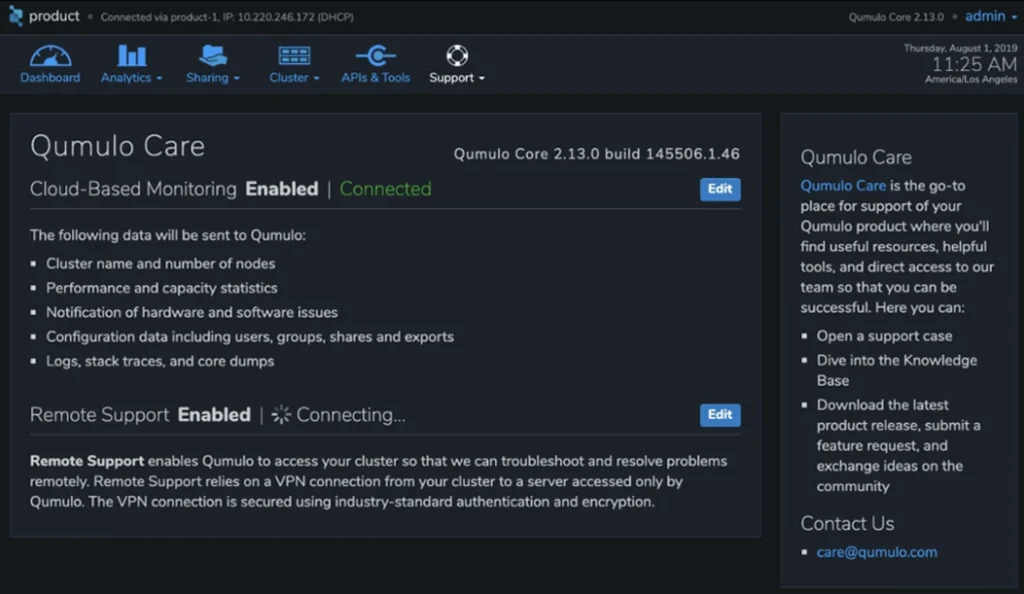
Support
Cette section permet aux clients d'effectuer des mises à niveau logicielles avec Qumulo Instant Upgrade, de se connecter à la surveillance à distance et d'autoriser l'équipe de réussite client de Qumulo à se connecter à distance à un système Qumulo.
Points d'innovation
L'API Qumulo offre un sur-ensemble complet de toutes les fonctionnalités de la plate-forme de données de fichiers Qumulo, permettant aux clients de développer avec le logiciel Qumulo et de gérer leur système Qumulo entièrement via des outils de gestion d'infrastructure modernes.
L'interface visuelle Qumulo offre des outils simples (et compréhensibles) pour gérer les systèmes Qumulo, ce qui réduit les dépenses informatiques en termes de coût et de temps.
Le tableau de bord et l'interface visuelle d'analyse fournissent des informations exploitables en temps réel sur n'importe quelle plate-forme de données de fichiers Qumulo. Les utilisateurs peuvent comprendre à quel point leur plate-forme de données de fichiers Qumulo sert les créateurs et offre des informations sur les charges de travail de ces créateurs.
Services de données
Objectif
Protégez, sécurisez et gérez les données dans la plate-forme de fichiers Qumulo à l'aide des outils de niveau entreprise que les DSI et les OSC attendent des plates-formes de données.
Comment ça marche
La couche Data Services est composée de cinq fonctionnalités: instantanés, réplication, quotas, audit, contrôle d'accès basé sur les rôles (RBAC) et passage à Amazon S3.
Instantanés
Les données stockées dans une plate-forme de données de fichiers Qumulo peuvent être visualisées à la fois dans leur forme actuelle et dans les versions précédentes via des instantanés. Ces instantanés utilisent une méthodologie d'écriture déplacée unique qui ne consomme de l'espace que lorsque des modifications se produisent. Cela rend les instantanés de Qumulo à la fois efficaces et performants. Les instantanés sont contrôlés par une stratégie d'instantanés qui définit la partie de l'espace de noms à protéger, la fréquence des instantanés et la durée de conservation des instantanés.
Les stratégies de snapshots peuvent être liées aux stratégies de réplication. Cela permet de répliquer les instantanés sur une deuxième plate-forme de données de fichiers Qumulo et de conserver des instantanés fréquents sur une plate-forme de données de fichiers Qumulo et des instantanés moins fréquents sur une autre (une stratégie commune de protection contre la perte de données d'entreprise et les ransomwares). Les administrateurs peuvent restaurer des instantanés et des fichiers individuels peuvent être restaurés via l'interface visuelle / CLI / API, ou directement par les utilisateurs finaux via des outils clients (par exemple «Versions précédentes» sous Windows). La limite du nombre total de clichés dans une plate-forme de données de fichiers Qumulo est mesurée en dizaines de milliers, plus élevée que la plupart des autres systèmes.
réplication
La réplication permet aux utilisateurs de copier, déplacer et synchroniser des données sur plusieurs plates-formes de données de fichiers Qumulo. Notre technologie de réplication offre deux fonctionnalités essentielles: un mouvement efficace des données et une identification granulaire des données modifiées. La réplication de Qumulo est continue, ce qui signifie que toute nouvelle modification d'un répertoire répliqué sera identifiée et déplacée, asynchrone et unidirectionnelle. Notre technologie de réplication exploite les instantanés pour créer une liste des régions de fichiers modifiées au cours d'une période donnée, qui sont ensuite déplacées vers une deuxième plate-forme de données de fichiers Qumulo via un protocole de transfert de données crypté. La liste des fichiers modifiés est disponible comme son propre point de terminaison d'API, que les éditeurs tiers utilisent pour intégrer Qumulo dans les systèmes de sauvegarde de données. La réplication de Qumulo fonctionne sur deux plates-formes de données de fichiers Qumulo, y compris sur site vers cloud, cloud vers cloud et dans les régions cloud. La réplication est utilisée pour activer la sauvegarde à l'échelle du pétaoctet, en particulier lorsqu'elle est associée à une reprise après sinistre de réplication d'instantané, y compris le basculement et la restauration. Il permet également le cloud hybride et l'éclatement du cloud, une infrastructure multicloud et multirégionale et des scénarios de collaboration à distance.
Changement de Qumulo vers Amazon S3
La réplication du magasin d'objets permet à toute plate-forme de données de fichiers Qumulo de traiter un service de stockage d'objets dans le cloud (par exemple Amazon S3) comme une cible de réplication appropriée. Les utilisateurs peuvent copier des données d'un espace de noms Qumulo vers un magasin d'objets cloud via Qumulo Shift une fois, ou de manière continue, et vice versa. Les données déplacées vers un magasin d'objets sont stockées dans un format ouvert et non propriétaire permettant aux créateurs d'exploiter ces données via des applications qui se connectent directement au magasin d'objets cloud Amazon S3, au format natif Amazon S3. Les exemples de scénarios incluent l'archivage des données d'un espace de noms Qumulo vers des niveaux de stockage à froid d'objets cloud Amazon S3, ou l'activation des services d'apprentissage automatique basés sur les données Amazon S3 pour traiter les données qui ont été capturées et modifiées sur une plate-forme de données de fichiers Qumulo.
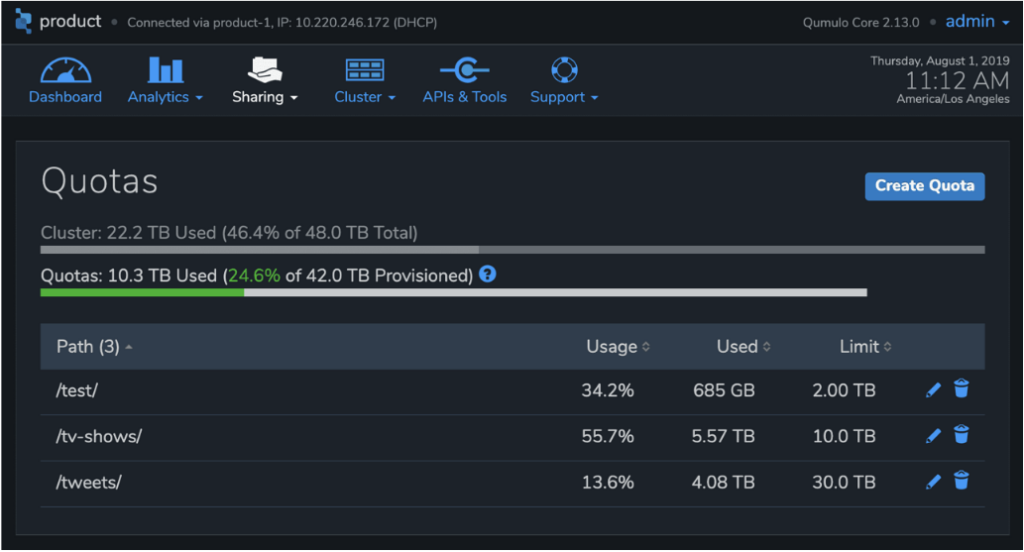
Quotas
Les quotas permettent aux utilisateurs de contrôler la croissance de n'importe quel sous-ensemble d'un espace de noms Qumulo. Les quotas agissent comme des limites indépendantes sur la taille de n'importe quel répertoire, empêchant la croissance des données lorsque la limite de capacité est atteinte. Contrairement à d'autres produits, les quotas Qumulo prennent effet instantanément, ce qui permet aux administrateurs d'identifier les charges de travail malveillantes à l'aide de nos analyses de capacité en temps réel et d'arrêter instantanément l'utilisation rampante de la capacité. Les quotas suivent même la partie de l'espace de noms qu'ils couvrent lorsque les répertoires sont déplacés ou renommés.
Audit
L'audit permet aux administrateurs de sécurité de suivre toutes les actions entreprises dans un espace de noms Qumulo et les modifications de configuration du système. L'audit capture tous les accès et modifications aux données, les tentatives d'accès à une plate-forme de données de fichiers Qumulo, le partage de données via de nouveaux partages ou exportations, et les modifications de la configuration du système ou des schémas de protection des données. Audit envoie ces journaux d'activité à n'importe quel serveur syslog distant standard.
Contrôle d'accès basé sur les rôles
Le contrôle d'accès basé sur les rôles (RBAC) permet aux administrateurs de sécurité d'utiliser leurs services d'identité pour contrôler quels utilisateurs ou groupes ont le droit d'apporter des modifications à une plate-forme de données de fichiers Qumulo ou d'afficher l'interface visuelle. RBAC propose plusieurs «rôles» préconfigurés qui ont le droit d'agir dans ou sur le système (administrateur, observateur, administrateur de données). Les administrateurs ajoutent des utilisateurs et des groupes AD ou LDAP à ces rôles. Les administrateurs peuvent également créer des rôles personnalisés pour correspondre à des régimes de sécurité uniques dans leur organisation (par exemple, un rôle «d'administrateur de sauvegarde»).
Points d'innovation
Qumulo Shift copie les données du fichier au format d'objet Amazon A3 natif afin que les données puissent être facilement utilisées par les services cloud AWS natifs.
Les instantanés de la plate-forme de données de fichiers de Qumulo sont efficaces, performants et évolutifs (jusqu'à 40k ou plus).
La réplication de snapshot permet une sauvegarde intégrée à l'échelle du pétaoctet pour toute plate-forme de données de fichiers Qumulo, où qu'elle se trouve.
La réplication permet à toute plate-forme de données de fichiers Qumulo de copier, déplacer ou synchroniser des données vers n'importe quelle autre plate-forme de données de fichiers Qumulo (depuis le site vers le cloud, de la région du cloud vers la région du cloud ou à travers les clouds).
Les quotas dans Qumulo sont en temps réel et ne nécessitent pas de longues énumérations de plates-formes de données (également appelées «parcours d'arbres») pour prendre effet.
Audit s'intègre simplement avec des outils de gestion d'infrastructure modernes tels que Splunk.
Le système de fichiers Qumulo
Objectif
Organisez les données dans des structures compréhensibles, activez les charges de travail avec un nombre important de fichiers, donnez aux créateurs la possibilité de collaborer sur des ensembles de données au fur et à mesure de leur progression dans le cycle de vie des données, et fournissez des informations en temps réel sur les performances et l'utilisation de la capacité, même lorsque les systèmes évoluent jusqu'à des pétaoctets et des milliards de fichiers .
Comment ça marche
Le système de fichiers Qumulo organise toutes les données stockées dans un système Qumulo dans un espace de noms. Cet espace de noms est compatible POSIX et conserve les autorisations et les informations d'identité qui prennent en charge la sémantique complète disponible sur les protocoles NFS ou SMB. Comme toutes les plates-formes de données de fichiers, la plate-forme de données de fichiers Qumulo organise les données dans des répertoires et présente les données aux clients SMB et NFS. Cependant, la plate-forme de données de fichiers Qumulo a plusieurs propriétés uniques: l'utilisation d'arbres B, un moteur d'analyse en temps réel et des autorisations inter-protocoles (XPP).
Arbres B dans la plate-forme de données de fichiers
La plate-forme de données de fichiers Qumulo peut évoluer jusqu'à des milliards de fichiers sans rencontrer les problèmes courants sur d'autres plates-formes, tels que le manque de ralentissements des inodes, l'inefficacité et la récupération en cas de défaillance de composants longs. Nous accomplissons cela en utilisant une collection de technologies, dont l'une est le B-tree. Les arbres B sont particulièrement adaptés aux systèmes qui lisent et écrivent un grand nombre de blocs de données car ce sont des structures de données «superficielles» qui minimisent la quantité d'E / S requise pour chaque opération à mesure que la quantité de données augmente. Avec les arbres B comme base, le coût de calcul de la lecture ou de l'insertion de blocs de données augmente très lentement à mesure que la quantité de données augmente.
Par exemple, les arbres B sont idéaux pour les plates-formes de données de fichiers et les index de base de données très volumineux. Dans la plate-forme de données de fichier de Qumulo, les arbres B sont basés sur des blocs. Chaque bloc fait 4096 octets et chaque bloc 4K peut avoir des pointeurs vers d'autres blocs 4K. La plate-forme de données de fichiers Qumulo utilise des arbres B à de nombreuses fins différentes. Il existe un arbre B inode, qui agit comme un index de tous les fichiers. La liste des inodes est une technique d'implémentation de plate-forme de données de fichiers standard qui rend la vérification de la cohérence de la plate-forme de données de fichiers indépendante de la hiérarchie des répertoires. Les inodes aident également à rendre les opérations de mise à jour, telles que les déplacements de répertoires, efficaces. Les fichiers et répertoires sont représentés sous forme d'arbres B avec leurs propres paires clé / valeur, telles que le nom du fichier, sa taille et sa liste de contrôle d'accès (ACL) ou les autorisations POSIX. Les données de configuration sont également un arbre B et contiennent des informations telles que l'adresse IP du cluster.
Moteur d'analyse en temps réel
Qumulo offre un aperçu de la capacité et de l'utilisation des performances des données dans une plate-forme de données de fichiers Qumulo. Cela permet aux clients de voir, presque instantanément, quelles parties de la plate-forme de données de fichiers ont augmenté (ou rétréci), quelles applications consomment des ressources de performance et quelles parties de la plate-forme de données de fichiers sont les plus actives. Cela permet aux clients de dépanner les applications, de gérer la consommation de capacité et de planifier en utilisant des données réelles. Ces informations reposent sur deux technologies: l'agrégation de métadonnées de capacité et l'échantillonnage de plate-forme de données de fichiers.
Agrégation de métadonnées de capacité
Dans la plate-forme de données de fichiers Qumulo, les métadonnées telles que les octets utilisés et le nombre de fichiers sont agrégées en tant que fichiers, et les répertoires sont créés ou modifiés. Cela signifie que les informations sont disponibles pour un traitement en temps opportun sans des parcours coûteux dans l'arborescence de la plate-forme de données de fichiers. Le moteur d'analyse en temps réel maintient des résumés de métadonnées à jour dans l'espace de noms de la plate-forme de données de fichiers. Il utilise les arbres B de la plate-forme de données de fichiers pour collecter des informations sur la plate-forme de données de fichiers lorsque des changements se produisent. Divers champs de métadonnées sont résumés dans la plate-forme de données de fichiers pour créer un index virtuel. Au fur et à mesure des modifications, de nouvelles métadonnées agrégées sont collectées et les modifications sont propagées des fichiers individuels à la racine de la plate-forme de données de fichiers.
Lorsque chaque fichier (ou répertoire) est mis à jour avec de nouvelles métadonnées agrégées, son répertoire parent est marqué comme obsolète et un autre événement de mise à jour est mis en file d'attente pour le répertoire parent. De cette manière, les informations de plate-forme de données de fichiers sont collectées et agrégées tout en étant transmises dans l'arborescence. Les métadonnées se propagent du nœud individuel, au niveau le plus bas, à la racine de la plate-forme de données de fichiers lors de l'accès aux données. Chaque opération de fichier et de répertoire est prise en compte.
Parallèlement à la propagation ascendante des événements de métadonnées, un parcours périodique commence en haut de la plate-forme de données de fichiers et lit les informations agrégées présentes dans les métadonnées. Lorsque le parcours trouve des informations agrégées récemment mises à jour, il élague sa recherche et passe à la branche suivante. Il suppose que les informations agrégées sont à jour dans l'arborescence de la plate-forme de données de fichiers à partir de ce point vers les feuilles, y compris tous les fichiers et répertoires contenus, et n'ont pas besoin d'aller plus loin pour des analyses supplémentaires. La plupart du résumé des métadonnées a déjà été calculé et, idéalement, le parcours n'a besoin que de résumer un petit sous-ensemble des métadonnées pour l'ensemble de la plate-forme de données de fichiers. En effet, les deux parties du processus d'agrégation se rencontrent au milieu sans avoir à explorer l'arborescence complète de la plate-forme de données de fichiers de haut en bas.
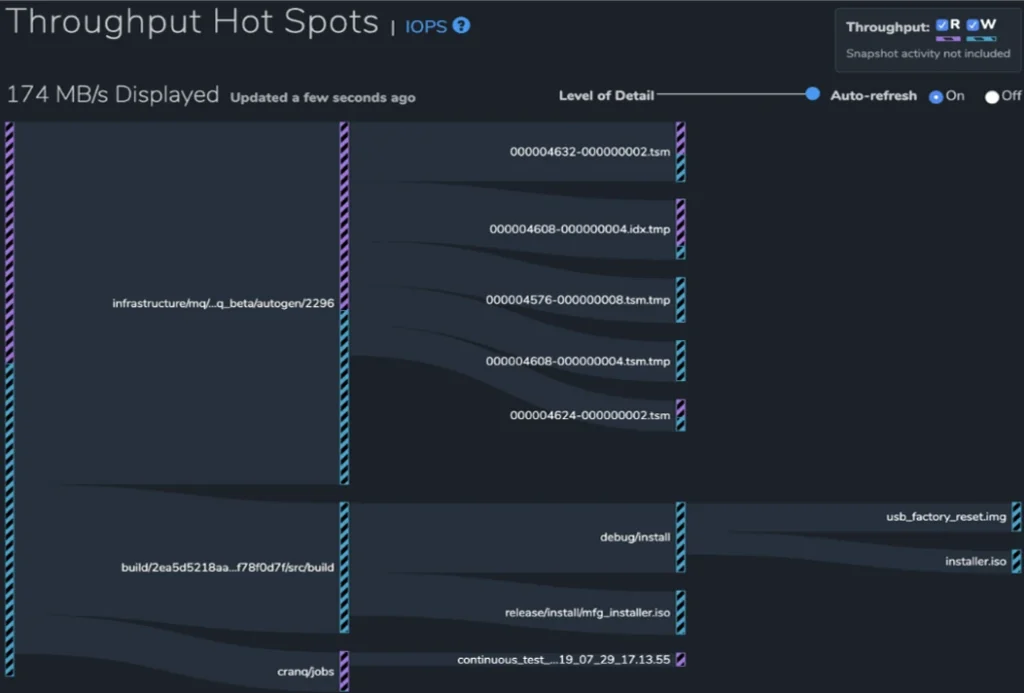
Échantillonnage du système de fichiers
Un exemple de l'analyse en temps réel de Qumulo est ses rapports sur les points chauds de performance. Représenter chaque opération de débit et IOPS dans l'interface visuelle serait impossible dans les plates-formes de données de fichiers volumineux. Au lieu de cela, le moteur d'analyse en temps réel de Qumulo utilise un échantillonnage probabiliste pour fournir une approximation statistiquement valide de ces informations. Les totaux des opérations de lecture et d'écriture d'IOPS, ainsi que les opérations de lecture et d'écriture du débit d'E / S, sont générés à partir d'échantillons collectés à partir d'un tampon en mémoire de dizaines de milliers d'entrées ou plus qui sont mis à jour toutes les quelques secondes.
Le rapport affiché affiche les opérations qui ont le plus grand impact sur le cluster. Ceux-ci sont représentés sous forme de hotspots dans l'interface visuelle.
La capacité de Qumulo à utiliser un échantillonnage probabiliste statistiquement valide n'est possible que grâce aux métadonnées résumées pour chaque répertoire (octets utilisés, nombre de fichiers) qui sont continuellement mis à jour par le moteur d'analyse en temps réel.
Autorisations inter-protocoles (XPP)
Afin de permettre aux créateurs de partager des données tout au long du cycle de vie de l'innovation, Qumulo doit permettre l'accès aux mêmes données par une variété de systèmes d'exploitation (par exemple Windows, Mac, Linux). Cependant, ces systèmes reposent sur NFS et SMB qui ont des langages très différents pour exprimer l'identité. Par exemple, un laboratoire pourrait créer des données à l'aide d'un séquenceur génomique, qui exécute Windows, et donc exprimer l'identité en utilisant le langage riche des ACE et des ACL. Ensuite, un chercheur peut analyser ces données à l'aide d'un client Windows, qui utilise également SMB et comprend donc les ACL. À un moment donné, le chercheur voudra coordonner une opération de calcul parallèle en utilisant un cluster HPC exécutant Linux, qui attend des autorisations POSIX (par exemple des bits de mode). L'organisme de recherche serait confronté au choix soit de simplifier toutes les autorisations à l'ensemble le moins restrictif, permettant ainsi l'accès requis, soit de déplacer les données dans un espace de noms entièrement séparé, ce qui interromprait le flux de collaboration et augmenterait les coûts informatiques.
Qumulo a résolu ce problème en créant une plate-forme de données de fichiers qui peut traduire et rationaliser plusieurs langues d'autorisation, de sorte que tout client verra les autorisations auxquelles il s'attend sans sacrifier l'expressivité du protocole. Nous appelons cette technologie XPP. Les autorisations croisées (XPP) permettent des flux de travail de protocoles SMB et NFS mixtes en préservant les ACL SMB, en conservant l'héritage des autorisations et en réduisant l'incompatibilité des applications liée aux paramètres d'autorisations.
Les autorisations inter-protocoles sont conçues pour fonctionner des manières suivantes:
- Lorsqu'il n'y a pas d'interaction entre protocoles, Qumulo fonctionne précisément selon les spécifications du protocole.
- Lorsque des conflits entre protocoles surviennent, les autorisations inter-protocoles minimisent la probabilité d'incompatibilités d'application.
- L'activation des autorisations inter-protocoles ne modifiera pas les droits sur les fichiers existants dans un système de fichiers. Les changements ne peuvent se produire que si les fichiers sont modifiés alors que le mode est activé.
Points d'innovation
La plateforme de données de fichiers Qumulo peut évoluer jusqu'à des milliards de fichiers tout en préservant une efficacité élevée, une résilience aux pannes de composants et des performances élevées.
Les clients peuvent diagnostiquer les flux de travail, identifier les applications qui se comportent mal, gérer la consommation de capacité et planifier l'avenir en utilisant des données en temps réel sur les performances et l'utilisation de la capacité, même sur des plates-formes de données de fichiers à l'échelle d'un milliard de pétaoctets.
Les créateurs peuvent collaborer tout au long du cycle de vie des données, en utilisant des outils standard pour les clients des utilisateurs finaux et le calcul HPC, à partir du même espace de noms Qumulo grâce aux autorisations inter-protocoles.
La plateforme de données de fichiers Qumulo peut évoluer jusqu'à des milliards de fichiers tout en préservant une efficacité élevée, une résilience aux pannes de composants et des performances élevées.
Les clients peuvent diagnostiquer les flux de travail, identifier les applications qui se comportent mal, gérer la consommation de capacité et planifier l'avenir en utilisant des données en temps réel sur les performances et l'utilisation de la capacité, même sur des plates-formes de données de fichiers à l'échelle d'un milliard de pétaoctets.
Les créateurs peuvent collaborer tout au long du cycle de vie des données, en utilisant des outils standard pour les clients des utilisateurs finaux et le calcul HPC, à partir du même espace de noms Qumulo grâce aux autorisations inter-protocoles.
Le magasin de blocs évolutif
Objectif
Apportez la plate-forme de données de fichiers Qumulo à n'importe quel environnement de cloud privé et public, activez une échelle massive, garantissez la cohérence à travers un système, protégez-vous contre les pannes de composants et alimentez des charges de travail interactives et hautes performances.
Comment ça marche
La base de la plate-forme de données de fichiers Qumulo est le Scalable Block Store (SBS). Le SBS exploite plusieurs technologies de base pour permettre l'évolutivité, la portabilité, la protection et les performances: un système de blocs virtualisés, un codage d'effacement, un système de transaction global et un cache intelligent.
Le système de blocs virtuels
La capacité de stockage d'un système Qumulo est organisée conceptuellement en un seul espace d'adressage virtuel protégé. Chaque adresse protégée dans cet espace stocke un bloc de 4 Ko d'octets. Chacun de ces «blocs» est protégé à l'aide d'un schéma de codage d'effacement pour assurer la redondance en cas de défaillance du périphérique de stockage. L'ensemble de la plate-forme de données de fichier est stockée dans l'espace d'adressage virtuel protégé fourni par SBS, y compris la structure de répertoire, les données utilisateur, les métadonnées de fichier, les analyses et les informations de configuration.
Le magasin protégé agit comme une interface entre la plate-forme de données de fichiers et les données basées sur des blocs enregistrées sur les périphériques de blocs attachés. Ces périphériques peuvent être des périphériques flash ou des disques durs, soit sur un serveur dédié dans le cloud privé, soit sur un serveur virtuel dans le cloud public. En utilisant des blocs 4K, le système de blocs virtuels permet un stockage très efficace de toutes les tailles de fichiers (grandes à petites).
Codage d'effacement
Chaque bloc virtuel fait partie d'un groupe de protection plus large appelé magasin protégé (ou pstore), qui exploite le codage d'effacement pour distribuer et protéger les données sur une plate-forme de données de fichiers Qumulo distribuée. Ce pstore est le conteneur organisateur de la protection des données. Dans et entre les pstores, les blocs de données tirent parti des algorithmes de Reed-Solomon pour créer des copies de «parité» des blocs de données qui sont utilisées pour reconstruire les blocs endommagés par une panne de composant. Le nombre de blocs de parité détermine la redondance du cluster avec des clusters plus grands nécessitant plus de redondance que les plus petits car ils contiennent plus de composants qui pourraient échouer. Ces pstores sont ensuite distribués sur une plate-forme de données de fichiers Qumulo pour contrôler les pannes de composants dans un serveur virtuel ou physique avec CPU, périphériques de stockage et réseau.
L'implémentation du codage d'effacement par Qumulo, associée à notre espace d'adressage virtuel granulaire, permet à la plate-forme de données de fichiers Qumulo de reconstruire rapidement et de manière prévisible les données à partir de composants défaillants. En outre, cela permet aux systèmes d'exploiter les supports flash et disques les plus denses disponibles dans le cloud public et privé, et d'exploiter des systèmes à grande échelle avec des performances fiables et de solides garanties de protection des données. Enfin, ce système de protection permet aux clients d'utiliser en toute confiance 100% de l'espace protégé disponible dans un système Qumulo, contrairement à d'autres systèmes qui fonctionnent mal ou de manière imprévisible au-delà de ~ 80% d'utilisation.
Le magasin protégé agit comme une interface entre la plate-forme de données de fichiers et les données basées sur des blocs enregistrées sur les périphériques de blocs attachés. Ces périphériques peuvent être des périphériques flash ou des disques durs, soit sur un serveur dédié dans le cloud privé, soit sur un serveur virtuel dans le cloud public. En utilisant des blocs 4K, le système de blocs virtuels permet un stockage très efficace de toutes les tailles de fichiers (grandes à petites).
Système de transaction global
Étant donné que Qumulo est une plate-forme de données de fichiers distribuée sans partage qui offre des garanties de cohérence immédiates, nous avons besoin d'un mécanisme pour garantir que chaque nœud du système a une vue cohérente de toutes les données. Nous accomplissons cela en nous assurant que toutes les lectures et écritures dans l'espace d'adressage virtuel sont transactionnelles.
Cela signifie que lorsqu'une opération de plate-forme de données de fichiers nécessite une opération d'écriture qui implique plusieurs blocs, l'opération écrira soit tous les blocs pertinents, soit aucun d'entre eux. Les opérations de lecture et d'écriture atomiques sont essentielles pour la cohérence des données et la mise en œuvre correcte des protocoles de fichiers tels que SMB et NFS. Pour des performances optimales, SBS utilise des techniques qui maximisent le parallélisme et le calcul distribué tout en maintenant la cohérence transactionnelle des opérations d'E / S. Par exemple, SBS est conçu pour éviter les goulots d'étranglement en série, où les opérations se dérouleraient dans une séquence plutôt qu'en parallèle. Le système de transaction de SBS utilise les principes de l'algorithme ARIES couramment utilisé dans les bases de données pour les transactions non bloquantes, y compris la journalisation à écriture anticipée, la répétition de l'historique pendant les actions «d'annulation» et la journalisation des actions «d'annulation».
Cependant, la mise en œuvre des transactions par SBS présente plusieurs différences importantes par rapport à ARIES. SBS tire parti du fait que les transactions initiées par la plate-forme de données de fichiers Qumulo sont, de manière prévisible, courtes, contrairement aux bases de données à usage général où les transactions peuvent être de longue durée. Un modèle d'utilisation avec des transactions de courte durée permet à SBS de couper fréquemment le journal des transactions pour plus d'efficacité. Les transactions de courte durée permettent une commande d'engagement plus rapide.
De plus, les transactions de SBS sont hautement distribuées et ne nécessitent pas de classement global défini et total des numéros de séquence de style ARIES pour chaque entrée du journal des transactions. Au lieu de cela, les journaux de transactions sont localement séquentiels dans chacun des blocs virtuels et coordonnés au niveau global, en utilisant un schéma de classement partiel qui prend en compte les contraintes d'ordre d'engagement.
L'approche de SBS présente l'avantage que la quantité minimale absolue de verrouillage est utilisée pour les opérations d'E / S transactionnelles, ce qui permet aux grappes Qumulo de s'adapter à plusieurs centaines de nœuds.
Mise en cache et prélecture intelligents
La plate-forme de données de fichiers Qumulo stocke des milliards de fichiers et des pétaoctets de capacité. Cependant, à un moment donné, seule une petite partie de ces données se trouve dans l'ensemble de travail actif d'un créateur ou d'un innovateur. Afin de garantir à ces créateurs les performances les plus rapides possibles, et donc d'empêcher les clients d'acheter des systèmes disparates à chaque étape du cycle de vie des données, Qumulo offre plusieurs garanties de performances dans notre produit:
1. Toutes les métadonnées, qui sont les plus souvent lues dans n'importe quel ensemble de données, résident sur le support durable le plus rapide du système (c'est-à-dire flash).
2. Les blocs virtuels lus fréquemment (mesurés par un « indice de chaleur » propriétaire) sont stockés sur mémoire flash, les blocs virtuels lus peu fréquemment sont déplacés vers des supports plus froids, le cas échéant.
3. Au fur et à mesure que les données sont lues, le système observe le comportement du client et précharge intelligemment les nouvelles données en mémoire sur le nœud le plus proche du client afin d'accélérer les temps d'accès. Nous y parvenons grâce à l'application intelligente d'une série de modèles prédictifs qui observent les schémas de dénomination des données, l'ordre de naissance des données et les modèles de lecture dans les fichiers volumineux. Le système exploite intelligemment le modèle le plus efficace pour n'importe quelle charge de travail et désactive les modèles inutiles.
Chiffrement au repos
Qumulo crypte automatiquement tous les systèmes au niveau du système de protection en utilisant le cryptage standard AES256 en mode XTS. En utilisant cette méthode, toutes les plates-formes de données de fichiers Qumulo sont protégées contre les attaques sur les composants sous-jacents. Le système présente une seule clé principale qui se trouve au-dessus de plusieurs clés de données et peut être tournée par le client. La combinaison de ce chiffrement logiciel avec la gestion des identités, la RBAC, l'audit et le chiffrement du trafic SMB et de réplication permet aux clients de répondre aux exigences de sécurité rigoureuses de l'entreprise.
Mise à jour instantanée
Qumulo est une société de développement de logiciels agile et, par conséquent, nous publions régulièrement de nouvelles améliorations. Nous voulons que nos clients puissent accéder rapidement et facilement à ces nouvelles améliorations.
Qumulo a conçu le processus de mise à niveau de Qumulo Core pour être rapide et facile. Qumulo Core est conteneurisé, ce qui nous permet de mettre à niveau un cluster entier, quelle que soit sa taille, en 20 secondes. En mettant en place un Qumulo Core secondaire, nous éliminons les restaurations puisque la fonctionnalité et la stabilité du Qumulo Core peuvent être démontrées avant qu'une mise à niveau ne se produise.
Échelle dynamique
Qumulo pense que vous ne devriez pas être empêché d'accéder aux dernières technologies. Les données se développent rapidement et vous avez besoin d'accéder à de nouvelles technologies pour suivre le rythme. Les fournisseurs hérités ne peuvent pas suivre le support logiciel pour les nouvelles innovations matérielles. Ces fournisseurs ont souvent besoin de mises à niveau de chariots élévateurs qui nécessitent une migration de données longue et complexe et / ou créent des pools de stockage complexes difficiles à gérer.
Qumulo offre une évolutivité dynamique avec compatibilité de nœud qui vous permet d'exploiter de nouveaux processeurs, stockage et mémoire dans les déploiements existants. Cette compatibilité des nœuds permet aux clients de continuer à développer facilement leurs clusters avec les nouvelles générations de systèmes. Tous les systèmes Qumulo auront un chemin vers des extensions vers de nouvelles générations de matériel et une configuration plus dense.
Points d'innovation
Le Qumulo SBS fait abstraction des composants matériels sous-jacents, permettant à la plate-forme de données de fichiers Qumulo de fonctionner dans des environnements de cloud public et privé.
Le SBS de Qumulo offre un stockage d'une efficacité unique sur toutes les tailles de fichiers.
La combinaison d'un système de blocs virtualisés et d'un codage d'effacement permet aux clients d'utiliser tout leur espace disponible et de tirer parti des périphériques de stockage les plus denses proposés dans le cloud privé et public.
Qumulo SBS permet aux clients de construire confortablement de très grands systèmes. Notre limite en mars 2020 est de 100 nœuds et 36 Po dans un espace de noms, bien que l'augmentation de cette limite soit une fonction de test, pas d'architecture.
Le système de transaction global de Qumulo permet des performances massivement évolutives avec un verrouillage distribué très efficace pour garantir une cohérence immédiate.
La mise en cache et la prélecture prédictives d'apprentissage automatique de Qumulo permettent des performances élevées sur les données les plus actives tout en permettant aux systèmes de s'adapter suffisamment pour couvrir l'ensemble du cycle de vie des données d'innovation.
Qumulo Instant Upgrade permet aux clusters de toute taille d'être mis à niveau en 20 secondes, éliminant ainsi la pré-planification et la surveillance constante de la plupart des mises à niveau d'infrastructure.
Conclusion
Qumulo a construit une plate-forme de données de fichiers qui peut servir tout le cycle de vie des données, de la capture, en passant par la transformation, à l'archivage, dans le cloud privé et public. Pour ce faire, Qumulo fournit un système prêt pour le cloud, évolutif, facile à utiliser. permet aux créateurs d'utiliser des outils standard, fournit des capacités d'automatisation et une visibilité et est sécurisé et prêt pour l'entreprise.
Prêt pour le cloud
La plate-forme de données de fichiers Qumulo est disponible dans le cloud public, privé et hybride.
Escaliers intérieurs
La plate-forme de données de fichiers Qumulo s'adapte en toute confiance à des milliards de fichiers et pétaoctets de données. La plate-forme de données de fichiers Qumulo évolue également en performances pour répondre aux exigences des charges de travail les plus difficiles.
Outils standards
La plateforme de données de fichiers Qumulo prend en charge les clients Windows, Mac et Linux.
Automatisation et visibilité
La plate-forme de données de fichiers Qumulo fournit une API robuste pour la programmabilité et l'automatisation et un aperçu en temps réel de la capacité et de l'utilisation des performances du système.
Sécurisé et prêt pour l'entreprise
La plateforme de données de fichiers Qumulo offre les outils d'identité, de contrôle, de gestion et de cryptage dont les entreprises ont besoin de leur infrastructure.
Découvrez Qumulo en action avec une démonstration
Découvrez comment gérer en toute simplicité vos données de fichiers à très grande échelle dans des environnements cloud hybrides